
DMOZ (from directory.mozilla.org, an earlier domain name) is a multilingual open-content directory of World Wide Web links. The site and community who maintain it are also known as the Open Directory Project (ODP). It is owned by AOL but constructed and maintained by a community of volunteer editors.
First, we would download a dump of their open directory from here contents. The content file has a nice structure and we would take advantage of it to extract useful data.
Topics are under 13 main categories which further have lots of subcategories.
Here are the root categories -

Subcategories under health -
For our URL classification problem, we will only focus on the root heirarchy.
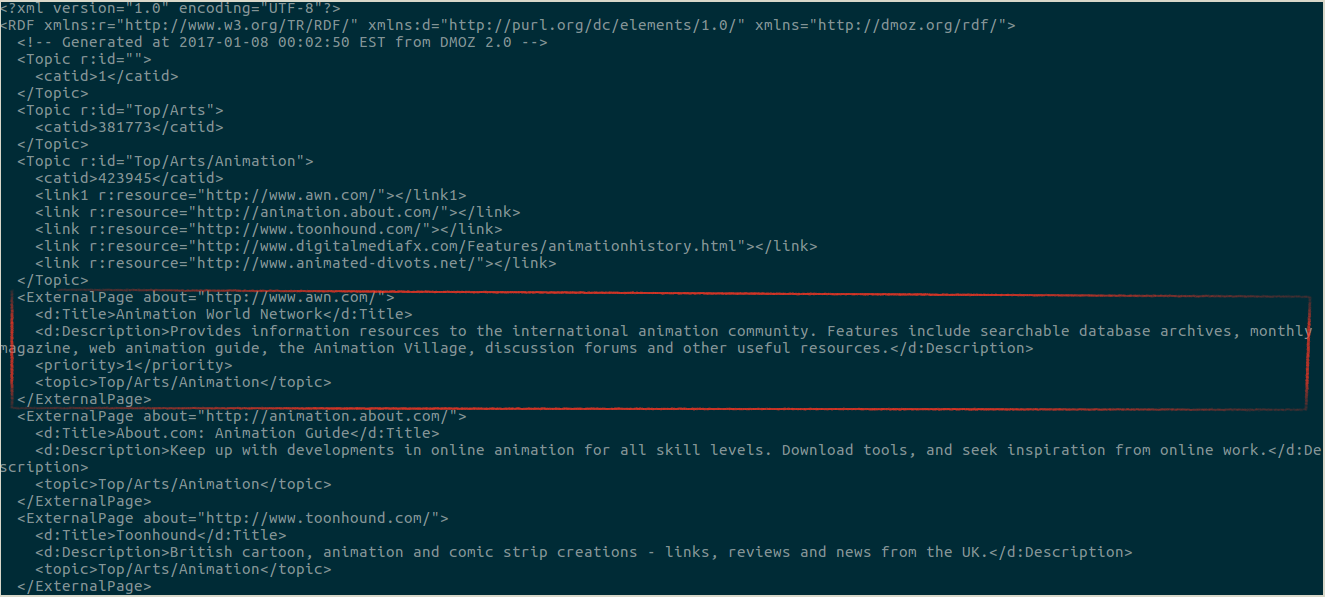
Below is the highlight of what we are looking for in the contents file.
Let’s get started
Import modules
import os
import sys
import re
import pandas as pd
import time
import numpy as np
import pickle
from collections import Counter
import keras
from keras import backend as K
from keras.utils.data_utils import get_file
from keras.utils import np_utils
from keras.utils.np_utils import to_categorical
from keras.models import Sequential, Model
from keras.layers import Input, Embedding, Reshape, merge, LSTM, Bidirectional
from keras.layers import TimeDistributed, Activation, SimpleRNN, GRU
from keras.layers.core import Flatten, Dense, Dropout, Lambda
from keras.regularizers import l2, activity_l2, l1, activity_l1
from keras.layers.normalization import BatchNormalization
from keras.optimizers import SGD, RMSprop, Adam
from keras.utils.layer_utils import layer_from_config
from keras.metrics import categorical_crossentropy, categorical_accuracy
from keras.layers.convolutional import *
from keras.preprocessing import image, sequence
from keras.preprocessing.text import Tokenizer
from sklearn import preprocessing, cross_validation, metrics, naive_bayes, pipeline, \
feature_extraction
import operator
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('ggplot')
%matplotlib inline
Using Theano backend.
Using gpu device 0: GeForce GTX 980 (CNMeM is enabled with initial size: 70.0% of memory, cuDNN 5005)
Read data
We will create an empty dataframe here which we would use afterwards to store categories, titles and descriptions of URLs.
path = '/home/dcrush/Documents/Url Classifier'
fn = 'content.rdf.u8'
# initialise empty dataframe
df = pd.DataFrame(columns=['category', 'title', 'desc'])
# we will read everything in one go and then filter out useful stuff
with open(os.path.join(path, fn), 'r') as fl_in:
lines = fl_in.readlines()
Filter titles, descriptions and topics
lines = [str(line) for line in lines]
titles = [re.findall('<d:Title>(.+)</d:Title>', line) for line in lines]
descs = [re.findall('<d:Description>(.+)</d:Description>', line) for line in lines]
topics = [re.findall('<topic>(.+)</topic>', line) for line in lines]
del lines
Let’s check positions as well as counts of titles, descriptions and topics.
titles_pos = [i for i, x in enumerate(titles) if len(x)>0]
descs_pos = [i for i, x in enumerate(descs) if len(x)>0]
topics_pos = [i for i, x in enumerate(topics) if len(x)>0]
print '# titles found', len(titles_pos)
print '# descriptions found', len(descs_pos)
print '# topics found', len(topics_pos)
# titles found 3579877
# descriptions found 3578583
# topics found 3579877
Ideally, lengths of titles_pos, descs_pos and topics_pos should all be same. Here we have some missing descriptions.
Let’s filter out only those cases where occupied index of descriptions is titles_index+1 and occupied index of topics is titles_index+2.
topics_list = []
titles_list = []
descs_list = []
for line_counter, i in enumerate(titles_pos):
if line_counter % 1000000 == 0:
print line_counter, 'processed'
if len(descs[i+1])>0 and len(topics[i+2])>0:
topics_list.append(topics[i+2][0].split('/')[1])
titles_list.append(titles[i][0])
descs_list.append(descs[i+1][0])
0 processed
1000000 processed
2000000 processed
3000000 processed
Write to dataframe
df.category = topics_list
df.title = titles_list
df.desc = descs_list
df.shape
(3534499, 3)
df.head()
| category | title | desc | |
|---|---|---|---|
| 0 | Arts | About.com: Animation Guide | Keep up with developments in online animation ... |
| 1 | Arts | Toonhound | British cartoon, animation and comic strip cre... |
| 2 | Arts | Digital Media FX: The History of Animation | Michael Crandol takes an exhaustive look at th... |
| 3 | Arts | Richard's Animated Divots | Chronology of animated movies, television prog... |
| 4 | Arts | Nini's Bishonen Dungeon | Shrines to Vega, Taiki, Dilandau, and Tiger Ey... |
df.tail()
| category | title | desc | |
|---|---|---|---|
| 3534494 | World | Tébabet tor békiti | Saghlamliq we tébabet heqqide. Eng yéngi yolla... |
| 3534495 | World | Tengritagh uyghur tori | Shinjang uyghur aptonom rayonluq xelq hökümiti... |
| 3534496 | World | Erkin asiya radiosi | Xewerler, mulahizeler, köpxil wasteler. Radio ... |
| 3534497 | World | Uyghurlar tori | Aile we turmush, ata-anilar, aliy mektep we ya... |
| 3534498 | World | Istiqlal radio-tilivizisi | Sherqi türküstan xewerliri, türk dünyasi xewer... |
Some of the stuff here is not english.
Let’s explore the distribution of categories we are dealing with.
df = pd.read_csv(os.path.join(path, 'contents.csv'))
plt.figure(figsize=(12, 5))
df.category.value_counts().plot(kind='bar');
plt.title('Category counts');
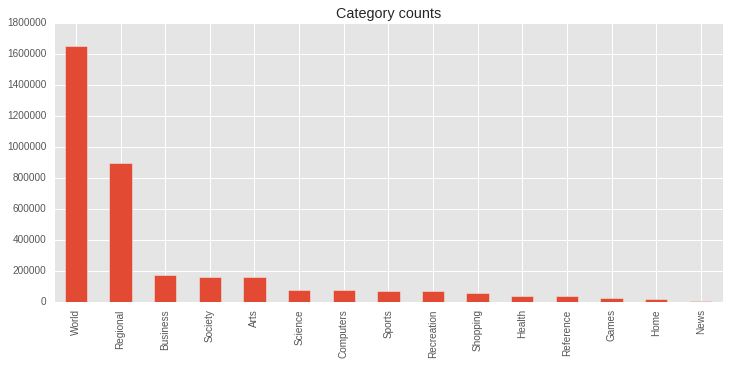
We will drop World and Regional from our model as they have multiple langauges as well as they make the data very skewed thus making our job difficult :)
print 'df shape before', df.shape
df = df[~df.category.isin(['World', 'Regional'])]
print 'df shape after', df.shape
df shape before (3534499, 3)
df shape after (981070, 3)
plt.figure(figsize=(12, 5))
df.category.value_counts().plot(kind='bar');
plt.title('Category counts');
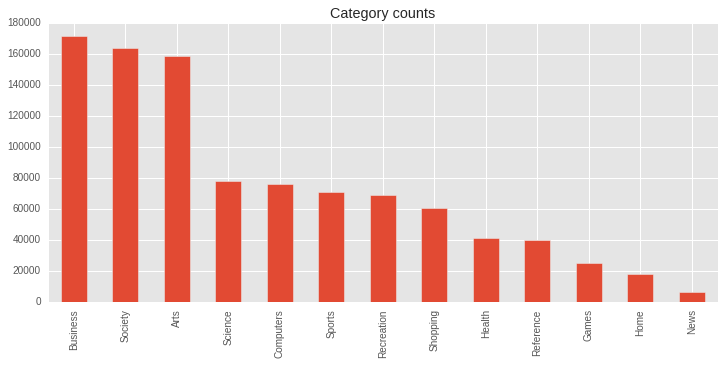
There is still a lot of class imbalance and this will surely affect our model. We are going to ignore this but there are many ways to handle this -
- Get more data for classes with less data
- Undersample
BusinessandSociety - Create synthetic data
First we will create a baseline model using naive-bayes
df.desc = df.title + ' ' + df.desc
df = df.drop(['title'], axis=1)
df.desc = df.desc.str.lower()
pipe = pipeline.Pipeline([('vect', feature_extraction.text.CountVectorizer()),
('tfidf', feature_extraction.text.TfidfTransformer()),
('gnb', naive_bayes.BernoulliNB())])
le = preprocessing.LabelEncoder()
le.fit(df.category)
y_data = le.transform(df.category)
X_data = df.desc.values
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X_data, y_data, \
test_size=0.2, random_state=1000)
pipe.fit(X_train, y_train)
Pipeline(steps=[('vect', CountVectorizer(analyzer=u'word', binary=False, decode_error=u'strict',
dtype=<type 'numpy.int64'>, encoding=u'utf-8', input=u'content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
st... use_idf=True)), ('gnb', BernoulliNB(alpha=1.0, binarize=0.0, class_prior=None, fit_prior=True))])
print metrics.classification_report(pipe.predict(X_test), y_test, target_names=le.classes_)
precision recall f1-score support
Arts 0.90 0.67 0.77 42549
Business 0.83 0.74 0.78 38300
Computers 0.74 0.77 0.75 14581
Games 0.28 0.97 0.43 1495
Health 0.63 0.87 0.73 5854
Home 0.22 0.98 0.36 809
News 0.00 0.00 0.00 0
Recreation 0.69 0.77 0.73 12343
Reference 0.33 0.66 0.44 4059
Science 0.62 0.71 0.66 13551
Shopping 0.62 0.73 0.67 10406
Society 0.82 0.70 0.75 38575
Sports 0.85 0.87 0.86 13692
avg / total 0.78 0.73 0.75 196214
Seems pretty decent. Let’s see if our next model can beat this.
We are going to model a CNN using word embeddings which we are going to build using the descriptions. To that end, we will concat title and description.
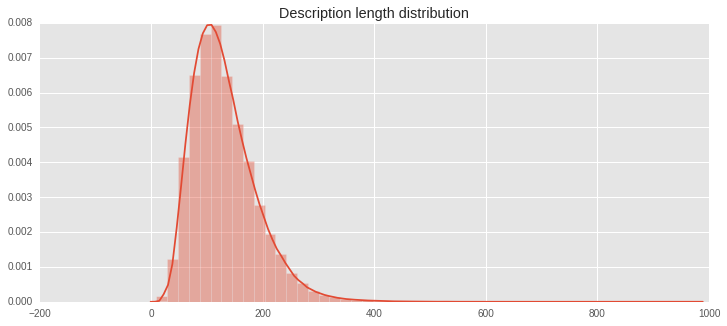
Let’s explore the lengths of descriptions we are looking at
lens = [len(x) for x in df.desc]
plt.figure(figsize=(12, 5));
print max(lens), min(lens), np.mean(lens)
sns.distplot(lens);
plt.title('Description length distribution');
978 10 131.182213298
Word dictionary
We need to create a word dictionary which would be used for word-id mapping. We will limit description length to 200 words. So when testing, we can only use max 200 words. Also, we will limit our vocabulary to 5000 words.
vocab_size = 5000
seq_len = 200
words = [re.findall('[\w\d]+', x) for x in df.desc]
all_words = []
for x in words:
all_words += x
word_to_id = Counter(all_words).most_common(vocab_size)
Top 10 most frequent words
word_to_id[:10]
[('and', 1271555),
('of', 575053),
('the', 507656),
('in', 298967),
('a', 246295),
('for', 231537),
('information', 183775),
('to', 183742),
('on', 127852),
('s', 110210)]
Least common words in our vocab
word_to_id[-10:]
[('directed', 384),
('outsourcing', 384),
('arbor', 384),
('roof', 383),
('perry', 383),
('hungary', 383),
('psi', 383),
('theta', 383),
('operate', 383),
('whether', 382)]
These words don’t seem to be that rare. We could increase our vocabulary size but we won’t as it would increase our training time as well.
We don’t care about the counts, so we will create a dictionary for these 5000 words with values in ascending order of count
word_to_id = {x[0]:i for i, x in enumerate(word_to_id)}
train = [np.array([word_to_id[y] if y in word_to_id else vocab_size-1\
for y in x]) for x in words]
Pad cases with length less than seq_len
train = sequence.pad_sequences(train, maxlen=seq_len, value=0)
train = train.astype('float32')
CNN
y_data = to_categorical(y_data)
X_train, X_test, y_train, y_test = cross_validation.train_test_split(train, y_data, \
test_size=0.2, random_state=1000)
model = Sequential([
Embedding(vocab_size, 50, input_length=seq_len),
Dropout(0.1),
Convolution1D(64, 5, border_mode='same', activation='relu'),
Dropout(0.2),
Convolution1D(128, 5, border_mode='same', activation='relu'),
Dropout(0.2),
MaxPooling1D(),
Flatten(),
Dense(200, activation='relu'),
Dropout(0.3),
Dense(13, activation='softmax')])
model.compile(loss='categorical_crossentropy', optimizer=Adam(), \
metrics=['accuracy'])
model.fit(X_train, y_train, validation_data=(X_test, y_test), \
nb_epoch=3, batch_size=64)
Train on 784856 samples, validate on 196214 samples
Epoch 1/3
784856/784856 [==============================] - 137s - loss: 0.7116 - acc: 0.7755 - val_loss: 0.6708 - val_acc: 0.7859
Epoch 2/3
784856/784856 [==============================] - 136s - loss: 0.6933 - acc: 0.7801 - val_loss: 0.6619 - val_acc: 0.7872
Epoch 3/3
784856/784856 [==============================] - 135s - loss: 0.6810 - acc: 0.7834 - val_loss: 0.6629 - val_acc: 0.7889
<keras.callbacks.History at 0x7f66be251150>
model.optimizer.lr = 1e-4
model.fit(X_train, y_train, validation_data=(X_test, y_test), \
nb_epoch=1, batch_size=64)
Train on 784856 samples, validate on 196214 samples
Epoch 1/1
784856/784856 [==============================] - 135s - loss: 0.6591 - acc: 0.7901 - val_loss: 0.6542 - val_acc: 0.7910
<keras.callbacks.History at 0x7f6685ab2c50>
preds = [np.argmax(x) for x in model.predict(X_test)]
y_test_argmax = [np.argmax(x) for x in y_test]
print metrics.classification_report(preds, y_test_argmax, target_names=le.classes_)
precision recall f1-score support
Arts 0.89 0.78 0.83 36431
Business 0.84 0.81 0.82 35628
Computers 0.81 0.77 0.79 16067
Games 0.67 0.83 0.74 4130
Health 0.82 0.75 0.78 8819
Home 0.65 0.77 0.71 2991
News 0.46 0.81 0.59 710
Recreation 0.68 0.82 0.75 11412
Reference 0.59 0.79 0.67 5994
Science 0.70 0.73 0.71 14908
Shopping 0.70 0.75 0.73 11403
Society 0.81 0.80 0.81 33066
Sports 0.91 0.87 0.89 14655
avg / total 0.80 0.79 0.79 196214
Results look much better now. Still, looks like class imbalance is playing a big role here.
I’ll be stopping here but feel free to make improvements and drop me a note.
Some things to try -
- Training the model for longer duration
- Resolving the class imbalance
- Using pretrained word vectors like Glove
- Make sure the model has enough variance to generalize. Usually this can be achieved by using data from other sources as well in the model
I haven’t covered how to use this model for real life data. I’ll do it in another post. The basic idea is to scrape content from URLs, expecially headings and paragraph tags, then preprocess them using the same pipeline we used for our training.
This post has been inspired by MOOC at Fast.ai, by Jeremy Howard.